
When studying the classical linear regression model, one necessarily comes across the Gauss-Markov Theorem. The Gauss-Markov Theorem is a central theorem for linear regression models. It states different conditions that, when met, ensure that your estimator has the lowest variance among all unbiased estimators. More formally, the Gauss-Markov Theorem tells us that in a regression model, where the expected value of our error terms is zero, i.e. 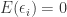
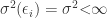



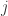
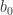
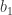
The reminder of the post summarizes the Gauss-Markov Theorem in a short, and hopefully intuitive way. However, if you are interested in a formal proof of the Gauss-Markov Theorem. You should check out this post here.
Suppose, we have the following regression model

Let’s start with shortly repeating how the point estimator for
(1)
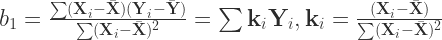
(2)

If you are not familiar with the linear regression model, you should first check out the following post. The exact derivation of the least squares estimator in matrix notation can be found here.
The variance of
(3)

Now, the Gauss-Markov Theorem is telling us that if its conditions are met, then
(4)
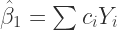
Furthermore, remember that the Gauss-Markov Theorem is telling us that the estimator has the lowest variance among all unbiased estimators. Hence, the estimator must be unbiased. Given the assumption of unbiasedness we know that 
(5)

(6)

(7)
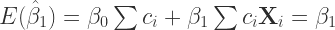
(8)

Note that, we can rewrite the definition of unbiasedness, i.e. 
In case you have not undestood everything, no worries. You can find the exact proof of the Gauss-Markov Theorem here.

Awesomme blog you have here
Thank you, glad you like it. It is quite some time I haven’t done anything here though, lets see, maybe I will be able to revive it 🙂