
From a previous posts on the Gauss Markov Theorem and OLS we know that the assumption of unbiasedness must full fill the following condition
(1)
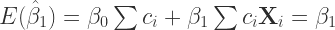
which means that 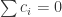
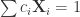
Looking at the estimator of the variance for
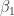
(2)
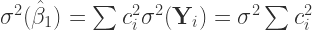
tells us that the estimator put additional restrictions on the 
To continue the proof we define 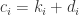
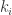
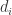

(3)
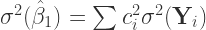
(4)
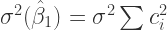
(5)
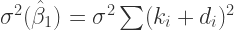
(6)
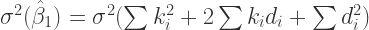
Note that Equation 6 is much more than just a transformation, it tells us that
(7)

Now, why do we need equation 7? Well, it shows us the relationship between 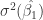
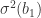
Finally, what we need to do to terminate the proof is to show that some of this extra stuff (
(8)
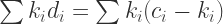
(9)
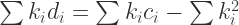
(10)
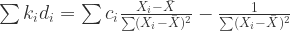
(11)
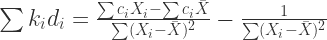
(12)
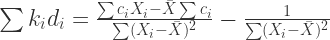
And as we know is
(13)
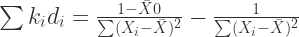
(14)
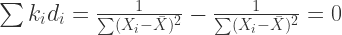
(15)
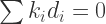
Having proofed that 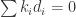
(16)

(17)
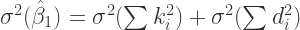
Now we will show that 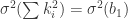
(18)
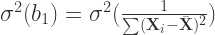
and from equation 1 we know that
(19)
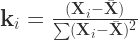
this lead us to
(20)
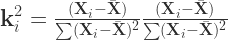
(21)
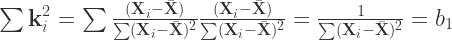
Finally, plugging in equation 21 into equation 17 gives us
(22)

So we are left with equation 22, which is minimized when 

If 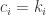

One thought on “Proof Gauss Markov Theorem”