
Clustered standard errors are a way to obtain unbiased standard errors of OLS coefficients under a specific kind of heteroscedasticity. Recall that the presence of heteroscedasticity violates the Gauss Markov assumptions that are necessary to render OLS the best linear unbiased estimator (BLUE).
The estimation of clustered standard errors is justified if there are several different covariance structures within your data sample that vary by a certain characteristic – a “cluster”. Furthermore, the covariance structures must be homoskedastic within each cluster. In this case clustered standard errors provide unbiased standard errors estimates.
You can find a review on heteroscedasticity and its consequences on the OLS estimator here. Various solutions to handle heteroscedasticity are described here.
Intuition of Clustered Standard Errors
The classical example that the literature tells to explain clustered standard errors uses student test scores form classes from different schools around a country. Let’s say you have a panel data set with different test scores from different classes from different schools around your country. Further, you are interested in the influence of class size on the test score. For instance, you want to test the hypothesis if smaller classrooms improve test scores. In your data, the test score varies on student level. However, class size varies only with class. In this case student test scores with a class are not independent. A class might have a better teacher or a better classroom community that provides a better learning environment.
Regressing class size on student test scores leaves you with standard errors that are heteroscedastic as the variance depends on the class. However, within each class – a class represents the cluster in this example – standard errors are homoscedastic.
Implementation of Clustered Standard Errors
In order to account for different covariance structures within your data that vary by a cluster, you want to relax the Gauss-Markov homoskedasticity assumption. Similar to heteroskedasticity-robust standard errors, you want to allow more flexibility in your variance-covariance (VCV) matrix. Recall that the diagonal elements of the VCV matrix are the squared standard errors of your estimated coefficients. The way to accomplish this is by using clustered standard errors. The formulation is as follows:
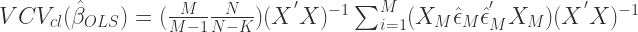
where 


This estimator 
Clustered Standard Errors in STATA
In STATA you can obtain clustered standard errors simply by adding cluster(cluster) to your regression command. For instance
reg dependent_var independent_var, cluster(cluster)
You can find a tutorial on how to calculate clustered standard errors in STATA here.
Clustered Standard Errors in R
It is also possible to estimate clustered standard errors in R. One can estimate clustered standard errors in R using the extended summary function. I extended the summary() in order to simplify the computation of clustered standard errors in R. My intention was to create a function that allows to compute clustered standard errors in a similar fashion as in STATA. If you are interested in calculating clustered standard errors in R click here. However, if you are more interested in the code and the exact extension of the summary() click here.

You write “Regressing class size on student test scores leaves you with standard errors that are heteroscedastic as the variance depends on the class.” Is that definitely true? Can’t you have homoscedasticity but still underestimate standard errors, as long as intraclass correlation coefficient > 0…?
The intuition I have is:
– Intraclass correlation coefficient > 0 means that the variance between individuals within a class is lower than the variance between individuals in the total sample
– This is due to unobservables (“better teacher” or “better learning environment”)
– Thus we effectively have less information than we think we do
– Unless we use clustered standard errors.
Am I misunderstanding?
-Andrew
Hi and thank you for reaching out,
I think that your four-bullet-point intuition is correct. I might even integrate it in my post, if you allow.
However, I do not agree with the first part of your statement. Homoscedasticity implies that the variance is constant for all observations in the sample. Hence, under homoscedasticity you cannot have that the variance between individuals within a class is lower than the variance between individuals in the total sample, right? Because by definition we assume that the variance is constant throughout the sample.
Nevertheless, it could be that I just misread your statement, so correct me if you think I am wrong.
Cheers, ad