Multicollinearity is a common problem in econometrics. As explained in a previous post, multicollinearity arises when we have too few observations to precisely estimate the effects of two or more highly correlated variables on the dependent variable. This post tries to graphically illustrate the problem of multicollinearity using venn-diagrams. The venn-diagrams below all represent the following regression model Continue reading Graphically Illustrate Multicollinearity: Venn Diagram→
Multicollinearity or collinearity refers to a situation where two or more variables of a regression model are highly correlated. Because of the high correlation, it is difficult to disentangle the pure effect of one single explanatory variables on the dependent variable . From a mathematical point of view, multicollinearity only becomes an issue when we face perfect multicollinearity. That is, when we have identical variables in our regression model. Continue reading The Problem of Multicollinearity→
In a previous post, we discussed how to obtain clustered standard errors in R. While the previous post described how one can easily calculate cluster robust standard errors in R, this post shows how one can include cluster robust standard errors in stargazer and create nice tables including clustered standard errors.
In a previous post, we discussed how to obtain robust standard errors in R. While the previous post described how one can easily calculate robust standard errors in R, this post shows how one can include robust standard errors in stargazer and create nice tables including robust standard errors.
The omitted variable bias is a common and serious problem in regression analysis. Generally, the problem arises if one does not consider all relevant variables in a regression. In this case, one violates the third assumption of the assumption of the classical linear regression model. The following series of blog posts explains the omitted variable bias and discusses its consequences.
Julia presents various ways to carry out multiple regressions. One easy way is to use the lm() function of the GLM package. In this post I will present how to use the lm() and run OLS on the following model
A linear regression is a special case of the classical linear regression models that describes the relationship between two variables by fitting a linear equation to observed data. Thereby, one variable is considered to be the explanatory (or independent) variable, and the other variable is considered to be the dependent variable. For instance, an econometrician might want to relate weight to their calorie consumption using a linear regression model.



 on the dependent variable
on the dependent variable 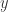 . From a mathematical point of view, multicollinearity only becomes an issue when we face perfect multicollinearity. That is, when we have identical variables in our regression model.
. From a mathematical point of view, multicollinearity only becomes an issue when we face perfect multicollinearity. That is, when we have identical variables in our regression model. 
