
The following post will give a short introduction about the underlying assumptions of the classical linear regression model (OLS assumptions), which we derived in the following post. Given the Gauss-Markov Theorem we know that the least squares estimator 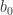
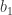
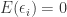
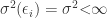



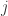
In the following we will summarize the assumptions underlying the Gauss-Markov Theorem in greater depth. In order for a least squares estimator to be BLUE (best linear unbiased estimator) the first four of the following five assumptions have to be satisfied:
Assumption 1: Linear Parameter and correct model specification
Assumption 1 requires that the dependent variable 


Assumption 2: Full Rank of Matrix X
Assumption 2 requires the matrix of explanatory variables X to have full rank. This means that in case matrix X is a 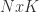

Assumption 3: Explanatory Variables must be exogenous
Assumption 3 requires data of matrix x to be deterministic or at least stochastically independent of 

The following post contains a more detailed description of assumption 3.
Assumption 4: Independent and Identically Distributed Error Terms
Assumption 4 requires error terms to be independent and identically distributed with expected value to be zero and variance to be constant. Mathematically is assumption 4 expressed as

The exact implications of Assumption 4 can be found here.
Assumption 5: Normal Distributed Error Terms in Population
Assumption 5 is often listed as a Gauss-Markov assumption and refers to normally distributed error terms 
Assumptions of Classical Linear Regression Models (CLRM)
Overview of all CLRM Assumptions
Assumption 1
Assumption 2
Assumption 3
Assumption 4
Assumption 5

Brilliant posting! One question and one comment.
Question: Should there not be a requirement for randomly sampled data? I have heard this should be one of the assumptions…
Comment: In assumption 3 additional details you comment: “The OLS estimator is neither consistent nor unbiased in case assumption 3 is violated. Unfortunately, we violate assumption 3 very easily. Common case that violate assumption 3 include omitted variables, measurement error and simultaneity.”
Doesn’t wrong functional form violate assumption 1 and not 3? The population errors seem like they could behave correctly even if wrong model is estimated… so I don’t see how that would violate 3. To assumption 1 it should be of course added that the model is estimateable by OLS.
Very appreciated if you can answer this as the literature is somewhat confusing. Thank you!
Hi! And thank you so much for your question and comment. I am always happy to get some remarks and comments. Let me start with some thoughts relating to your question. Don’t quote me on it, but if you do not have randomly sampled data, doesn’t it mean that your data selection process depends on a variable that should be included in the model? Because if that were to be true the variable would be missing and consequently show up in the error term and everything would boil down to an omitted variable problem.
Regarding your comment, it is definitively true that choosing a wrong functional form would violate assumption 1. However, I looked at the post on assumption 3 again and I couldn’t find me stating that a wrong functional form violates assumption 3. Correct me if I am wrong, but could it be that you equate a wrong functional form with an omitted variable problem? In my understanding these two problems are not identical, the functional form relates to the form of the function between the model and the dependent variable, while the omitted variable problem relates to a missing variable in the X matrix. Which is a different thing altogether. However, let me know if I misinterpreted your comment.
Nevertheless, I agree that I should be much clearer on this issue. I will revise the post as soon as I find some time.
I hope that my answer helped you in some way and let me know if you have any further questions.
Cheers!
FYI: The title of this post is currently “Assumptions of Classical Linerar Regressionmodels (CLRM)” but should be “Assumptions of Classical Linear Regression Models (CLRM)”
Thanks a lot, I’ll change it.
Sure! Thanks for making these posts.
What about cov(ei,ej)=0? or cov (ei,ej I Xi,Xj)=0. Please explain what are these eis.
In Population each Xi has a distribution of Ys generated though eis. So given Xi and Xj, we have two sets of vectors of eis( ekis(k=1to n1) for Xi and eljs(l=1 to n2) for Xj.
OR
it is related to sample data only where each xi has only one ei. In that case given Xi and Xj, there are only two es: ei and ej. Then what is the meaning of Cov(ei,ej).
I am not clear about the mechanics of this covariance.
I shall be grateful if you please explain by giving appropriate dataset of es.
cov(ei,ej)=0 where ei is differ from ej means there is no autocoreelation that means erorr in the previous period has no relation or has no effect on the next period.
well explained
Thanks a lot!
is there a possibility to refer to each paper? I mean I would like if you give me the original papers for the assumptions if possible!
Hi Yousef,
This is a very interesting question. I would actually have to a little digging to find out where the different assumptions of the linear regression models have been stated for the first time. As soon as time permits I’ll try to find out. In case you find them first, let me know, I’m very curious about it.
Best, ad
Are the OLS assumptions and the CLRM assumptions the same thing?
Yes!
Very much interested explanation… thanks again and again…
My pleasure, glad you liked it.