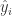Learning a new programming language is costly. Usually it takes a considerable amount of time to get acquainted with a new language. Especially the first phase can be painful and frustrating. The good thing is that with enough time and effort most of us will learn how to master a programming language eventually. However, note that, once we are comfortable with one language, we hardly want to change again. It turns out that the cost of abandoning on programming language and switch to another are even higher than at the beginning. Knowing this, we really want to make sure not to invest in the wrong language. There might be nothing worse than after finally mastering a programming language, recognizing that there is no use for this language anymore. While in a former post I highlighted reason why to use R, I concentrate on the Pros and Cons of R in this post.
Tag Archives: Econometrics
Why R?
Why should you use R?
There exists several reasons why one should start using R. During the last decade R has become the leading tool for statistics, data analysis, and machine learning. By now, R represents a viable alternative to traditional statistical programs such as Stata, SPSS, SAS, and Matlab. The reasons for R’s success are manifold. Continue reading Why R?
Clustered Standard Errors in R
The easiest way to compute clustered standard errors in R is the modified summary(). I added an additional parameter, called cluster, to the conventional summary() function. This parameter allows to specify a variable that defines the group / cluster in your data. The summary output will return clustered standard errors. Here is the syntax:
summary(lm.object, cluster=c("variable")) Continue reading Clustered Standard Errors in R
Example data – Clustered Standard Errors
The following R script creates an example dataset to illustrate the application of clustered standard errors. You can download the dataset here.
The script creates a dataset with a specific number of student test results. Individual students are identified via the variable student_id . The variable id_score comprises a student’s test score. In the test, students can score from 1 to 10 with 10 being the highest score possible. Continue reading Example data – Clustered Standard Errors
Robust Standard Errors in STATA
”Robust” standard errors is a technique to obtain unbiased standard errors of OLS coefficients under heteroscedasticity. In contrary to other statistical software, such as R for instance, it is rather simple to calculate robust standard errors in STATA. All you need to is add the option robust to you regression command. That is:
The Gauss Markov Theorem
When studying the classical linear regression model, one necessarily comes across the Gauss-Markov Theorem. The Gauss-Markov Theorem is a central theorem for linear regression models. It states different conditions that, when met, ensure that your estimator has the lowest variance among all unbiased estimators. More formally, Continue reading The Gauss Markov Theorem
Derivation of the Least Squares Estimator for Beta in Matrix Notation
The following post is going to derive the least squares estimator for 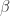
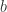
Continue reading Derivation of the Least Squares Estimator for Beta in Matrix Notation
Relationship between Coefficient of Determination & Squared Pearson Correlation Coefficient
The usual way of interpreting the coefficient of determination 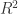
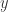
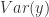
Another way of interpreting the coefficient of determination 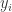
The Coefficient Of Determination or R2
The coefficient of determination