
This post is part of the series on the omitted variable bias and provides a simulation exercise that illustrates how omitting a relevant variable from your regression model biases the coefficients. The R code will be provided at the end.
Assume you are interest in second-hand cars and you want to find out what determines the prices of used cars. In order to answer this question, you collect a lot of data on cars, including all factors that you think might influence the price of a car. Finally, you end up having a data sample including 1’000 cars. For each car in your sample, you observe the price of the car, the brand of the car, the number of seats that a car has, whether the car already had an accident or not, the size of the car’s engine, the amount of kilometer it was already driven, and the age of the car.
In order to find out what drives the cars price you decide to estimate the following model using OLS:
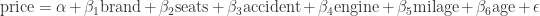
Now assume that for some reason you forget to include the variable age in your model. Estimating the model without the variable age will introduce an omitted variable bias and lead to biased estimates of your coefficient. Particularly, as miles and age are positively correlated and age has a negative impact on price, we the estimated coefficient of miles will exhibit a downward bias (read this post to learn more about the direction of the omitted variable bias). The table below presents the estimation results for the model presented above, once with and once without age. The OLS-estimation of the model including all relevant variables, estimates all coefficients correctly. However, neglecting the variable age leads to a biased estimate of the coefficient of the variable milage. Moreover, as predicted, neglecting the variable age leads to a downward bias of the estimate for the coefficient of the variable milage, i.e. the estimated coefficient decrease from -0.014 to -0.025.
| Dependent variable: price |
||
| (1) | (2) | |
| brand | 2,075.163*** | 2,090.848*** |
| (89.610) | (89.591) | |
| seats | 384.272*** | 376.811*** |
| (124.666) | (124.930) | |
| accident | -2,628.229*** | -2,588.826*** |
| (690.435) | (691.917) | |
| engine | 4.880*** | 4.865*** |
| (0.156) | (0.156) | |
| milage | -0.014** | -0.025*** |
| (0.006) | (0.003) | |
| age | -160.562** | |
| (66.507) | ||
| Constant | -342.778 | -633.799 |
| (821.856) | (814.939) | |
| Observations | 1,000 | 1,000 |
| R2 | 0.625 | 0.623 |
| Adjusted R2 | 0.623 | 0.621 |
| Residual Std. Error | 3,950.177 (df = 993) | 3,959.760 (df = 994) |
| F Statistic | 275.692*** (df = 6; 993) | 328.071*** (df = 5; 994) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | |
The following code allows you to replicate the example presented above. The code first simulates data sample including car prices and additional observables and estimates then the regression model, once with and once without the variable age.
# start with an empty workspace
rm(list=ls())
options(scipen=999)
set.seed(12345)
# simulate data
obs <- 1000 # number of observations
brand <- sample(c(1,2,3,4,5),obs,replace = T)
seats <- sample(c(4,4,5,5,5,7),obs,replace = T)
accident <- sample(c(rep(0,20),1),obs,replace = T)
engine <- sample(seq(1000,3600,200),obs,replace = T)
age <- sample(seq(1,16,1),obs,replace = T,
prob = c(0.04,0.06,0.08,0.11,
0.12,0.105,0.095,0.085,
0.07,0.06,0.05,0.04,
0.03,0.025,0.02,0.01))
milage <- age*10000*rnorm(obs,1,0.3)
error <- rnorm(obs,0,1)*4000
price <- round(brand*2000+seats*300-accident*2000+engine*5-
age*200-milage*0.01+error)
# estimate the model with and without age
reg1 <- lm(price~brand+seats+accident+engine+milage+age)
reg2 <- lm(price~brand+seats+accident+engine+milage)
require(stargazer)
stargazer(reg1,reg2,type = "text")
##

2 thoughts on “Omitted Variable Bias: An Example”