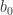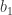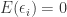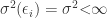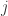This post shows how to manually construct the OLS estimator in R (see this post for the exact mathematical derivation of the OLS estimator). The code will go through each single step of the calculation and estimate the coefficients, standard errors and p-values. In case you are interested the coding an OLS function rather than in the step wise calculation of the estimation itself I recommend you to have a look at this post. Continue reading Calculate OLS estimator manually in R
Category Archives: Econometrics
CLRM – Assumption 5: Normal Distributed Error Terms in Population
Assumption 5 is often listed as a Gauss-Markov assumption and refers to normally distributed error terms 
Violation of CLRM – Assumption 4.1: Consequences when the expected value of the error term is non-zero
Violating assumption 4.1 of the OLS assumptions, i.e. 
CLRM – Assumption 4: Independent and Identically Distributed Error Terms
Assumption 4 of the four assumption required by the Gauss-Markov theorem states that the error terms of the population 

Proof Gauss Markov Theorem
From a previous posts on the Gauss Markov Theorem and OLS we know that the assumption of unbiasedness must full fill the following condition Continue reading Proof Gauss Markov Theorem
CLRM – Assumption 3: Explanatory Variables must be exogenous
Assumption 3, exogeneity of explanatory variables requires that the explanatory variables 
CLRM – Assumption 2: Full Rank of Matrix X
Assumption 2 requires the matrix of explanatory variables 
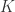

CLRM – Assumption 1: Linear Parameter and correct model specification
Assumption 1 requires that the dependent variable 


Continue reading CLRM – Assumption 1: Linear Parameter and correct model specification
Unbiased Estimator of Sample Variance – Vol. 2
Lately I received some criticism saying that my proof (link to proof) on the unbiasedness of the estimator for the sample variance strikes through its unnecessary length. Well, as I am an economist and love proofs which read like a book, I never really saw the benefit of bowling down a proof to a couple of lines. Actually, I hate it if I have to brew over a proof for an hour before I clearly understand what’s going on. However, in order to satisfy the need for mathematical beauty, I looked around and found the following proof which is way shorter than my original version.
Continue reading Unbiased Estimator of Sample Variance – Vol. 2
Assumptions of Classical Linear Regression Models (CLRM)
The following post will give a short introduction about the underlying assumptions of the classical linear regression model (OLS assumptions), which we derived in the following post. Given the Gauss-Markov Theorem we know that the least squares estimator