Violating assumption 4.1 of the OLS assumptions, i.e.  , can affect our estimation in various ways. The exact ways a violation affects our estimates depends on the way we violate . This post looks at different cases and elaborates on the consequences of the violation. We start with a less severe case and then continue discussing a far more sensitive violation of assumption 4.1.
, can affect our estimation in various ways. The exact ways a violation affects our estimates depends on the way we violate . This post looks at different cases and elaborates on the consequences of the violation. We start with a less severe case and then continue discussing a far more sensitive violation of assumption 4.1.
1st case of violating OLS assumption 4.1
The first case we consider is, when the conditional expected value of the error term  on
on  not zero, but a non-zero constant
not zero, but a non-zero constant  , i.e.
, i.e.  . One can show that violating in this case leads ”only” to wrongly estimated intercept, while the other beta coefficients are not affected. We demonstrate this with a simple example. Assume that
. One can show that violating in this case leads ”only” to wrongly estimated intercept, while the other beta coefficients are not affected. We demonstrate this with a simple example. Assume that 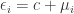 , where is a constant and
, where is a constant and  fulfills the usual error term characteristics, i.e.
fulfills the usual error term characteristics, i.e.  . In this case we can rewrite the model
. In this case we can rewrite the model 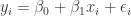 as
as

Note, because is constant it is added to the intercept. This follows from the mathematical rule that

In this case the OLS estimation of  is not affected by the violation of the assumption. However, we are not able to estimate
is not affected by the violation of the assumption. However, we are not able to estimate 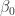 or
or 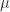 separately. The coefficient of the intercept rather provides the effect of the sum of both variables
separately. The coefficient of the intercept rather provides the effect of the sum of both variables 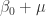 . In this case the data does not contain enough information to fully identify the effect of .
. In this case the data does not contain enough information to fully identify the effect of .
2nd case of violating OLS assumption 4.1
Things turn messy if the conditional expected value of the error term is not a constant but a function of the explanatory variables, i.e. .
We cannot solve the problem by including the intercept in this case. If we include an intercept it will only catch the magnitude that depends on the specific sample and realizations of . We can look at it that way, in case the conditional expected value of the error term is not a constant but rather a function of , our estimated coefficient of the intercept is not the coefficient of a constant anymore. It rather depends on through the non-constant conditional mean of the error term, i.e. 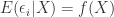 , where
, where 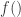 is a non-constant function.
is a non-constant function.
You will show that the OLS estimator will not be efficient anymore, if the conditional expected value of the error term is a function of the explanatory variables. In the following, you will find a mathematical demonstration of this statement. Assume that , i.e. the conditional expected value of the error term is a function of . Further, we will now derive the OLS estimator (you can find a more detailed derivation of the OLS estimator here) under this assumption. We start one step ahead of the usual notation of the basic OLS model by separating the intercept from the rest of the explanatory variables:

where  is the intercept. Mathematically is just a vector of ones. We now join and into matrix
is the intercept. Mathematically is just a vector of ones. We now join and into matrix 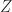 , where is nothing else than with the first column full of ones. Further, we join
, where is nothing else than with the first column full of ones. Further, we join 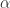 with
with 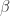 into
into  . This leaves us with
. This leaves us with
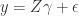
We derive the OLS estimator for the model above which leaves us with

where 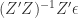 is the bias, which usually would disappear if or . However, in our case we have
is the bias, which usually would disappear if or . However, in our case we have
which is per assumption already non-zero for all  .
.
Consequently, if the conditional expected value of the error term is a function of the OLS estimator will be biased, even if we include an intercept in the regression. Further, this means also that we lose the Gauss-Markov result on efficiency. Finally, in the case that the conditional expected value of the error term is a function of the following holds true
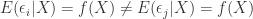
which means that  has a different mean and variance for each . In order words, the distribution of is conditional on and varies consequently across .
has a different mean and variance for each . In order words, the distribution of is conditional on and varies consequently across .
This has several implications on our estimator. First, we face heteroscedasticity. Second, we will have biased estimates of the coefficients and there is no way to say in which direction the bias goes. Note, not even the assumption of normal distributed error terms will solve this problem. Hence, hypothesis testing in no longer valid, if the conditional expected value of the error term is a function of . Put mildly different, but with the same meaning, we lose all finite sample properties.
Finally, you will better be careful with interpreting your findings, if the conditional expected value of the error term is a function of the explanatory variables . Nevertheless, if that is all you have you might want to draw asymptotically valid inferences. In order to do so, you have to fulfill different additional assumptions.
Assumptions of Classical Linerar Regressionmodels (CLRM)
Overview of all CLRM Assumptions
Assumption 1
Assumption 2
Assumption 3
Assumption 4
Assumption 5


Hello! Great post and overall great blog!
I was wondering if you could explain to me how we would check assumption 4 in practice. Do you use a plot? Is there a formal statistical test? Say, a command in R?
Thank you for your time!