The following post is going to derive the least squares estimator for 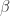 , which we will denote as
, which we will denote as 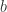 . In general start by mathematically formalizing relationships we think are present in the real world and write it down in a formula.
. In general start by mathematically formalizing relationships we think are present in the real world and write it down in a formula.
(1) 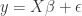
Formula (1) depicts such a model, where represents the true relationship between variables in our population. However, it is rare that we observe the whole population and with it the true relationship . Most times we observe just a small fraction of what is really going on in the world. Nevertheless, even if you just observe a faction, it is our job to estimate the true value as good as possible. One way to estimate the value of is done by using Ordinary Least Squares Estimator (OLS). In the following we we are going to derive an estimator for . The estimated values for will be called .
Assume we collected some data and have a dataset which represents a sample of the real world. Let the following equation (2) represent the mathematical model of relationships we presume to exist in the real world and consequently in our sample.
(2) 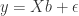
Equation (3) is supposed to present equation (2) in a more intuitively accessible way for those of you who still need some routine in reading matrix notation, however it is really just the same as equation (2).
(3) 
The idea of the ordinary least squares estimator (OLS) consists in choosing  in such a way that, the sum of squared residual (i.e.
in such a way that, the sum of squared residual (i.e. 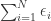 ) in the sample is as small as possible. Mathematically this means that in order to estimate the we have to minimize which in matrix notation is nothing else than
) in the sample is as small as possible. Mathematically this means that in order to estimate the we have to minimize which in matrix notation is nothing else than 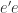 .
.
(4) 
In order to estimate we need to minimize . This is what we are going to do. Per definition we know that 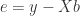 which follows directly from formula (2). Consequently we can write as
which follows directly from formula (2). Consequently we can write as 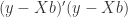 by simply plugging in the expression into . This leaves us with the following minimization problem:
by simply plugging in the expression into . This leaves us with the following minimization problem:
(5) 
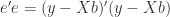
(6) 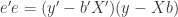
(7) 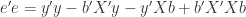
(8) 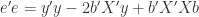
It is important to understand that 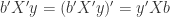 . As both terms are are scalars, meaning of dimension 1×1, the transposition of the term is the same term.
. As both terms are are scalars, meaning of dimension 1×1, the transposition of the term is the same term.
In order to minimize the expression in (8), we have to differentiate the expression in (8) with respect to and set the derivative equal zero. In order to be able to do that we make use of the following mathematical statements:
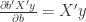
 (proof)
(proof)
Using the two statements allows us to minimize expression (8).
(8)
(9) 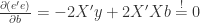
(10) 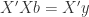
Finally to solve expression (9) for it is necessary to pre-multiply expression (10) with 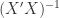 . This gives us the least squares estimator for .
. This gives us the least squares estimator for .
(11) 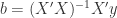
One last mathematical thing, the second order condition for a minimum requires that the matrix  is positive definite. This requirement is fulfilled in case
is positive definite. This requirement is fulfilled in case  has full rank.
has full rank.
Congratulation you just derived the least squares estimator .


Equation 3 has a typo:
You have put it as y = xb * error
It should be y = xb + error
You are right. Thank you!
Hi there! the matrix representation of the multivariable linear regression is clear thanks a lot for the post. I just wonder if the error vector should have (K,1) dimension instead of (N,1) dimension.
Thanks.
E.NGONGA
Hi Eric! Thank you for your comment. You are right, the vector should have (K,1) dimension instead of (N,1) dimension. I updated the post. Cheers!
Hello, great post!
“In order to be able to do that we make use of the following mathematical statements”: statement 2. isn’t clear to me, could you provide a brief explanation? Thanks!
Hi, thanks!
The two statements are the outcome of matrix derivation rules. Does that help you? If not, I can deliver a short mathematical proof that shows how derive these two statements.
Cheers
Can you show me the derivation of 2nd statements or document having matrix derivation rules.
Tks !
Thank you for you message.
I published the derivation of the 2nd statement in a separate post.
Hope it helps.
Cheers, ad
Very clearly written; logical and easy to follow. Thank you very much.
Thanks for the praise!
Very helpful. I understood much of this, which says a lot given my weak Linear Algebra.
I was surprised by this statement: “It is important to understand that b’X’y=(b’X’y)’=y’Xb.” … because “both terms are scalars.” Is b not a vector, y a vector, and X a matrix of observed data with d-dimensions or features?
Thanks for this comment. You really made ne think there. The term b’X’y is a scalar, because 1xn * n x n * 1 x n is 1 x 1. Hope this helps. Cheers, ad