There exists several reasons why one should start using R. During the last decade R has become the leading tool for statistics, data analysis, and machine learning. By now, R represents a viable alternative to traditional statistical programs such as Stata, SPSS, SAS, and Matlab. The reasons for R’s success are manifold. Continue reading Why R?→
Seasonal adjustment refers to a statistical technique that tries to quantify and remove the influences of predictable seasonal patterns to reveal nonseasonal changes in data that would otherwise be overshadowed by the seasonal differences. Seasonal adjustments provide a Continue reading Seasonal adjustment→
The easiest way to compute clustered standard errors in R is the modified summary(). I added an additional parameter, called cluster, to the conventional summary() function. This parameter allows to specify a variable that defines the group / cluster in your data. The summary output will return clustered standard errors. Here is the syntax:
The following R script creates an example dataset to illustrate the application of clustered standard errors. You can download the dataset here.
The script creates a dataset with a specific number of student test results. Individual students are identified via the variable student_id . The variable id_score comprises a student’s test score. In the test, students can score from 1 to 10 with 10 being the highest score possible. Continue reading Example data – Clustered Standard Errors→
The usual way of interpreting the coefficient of determination is to see it as the percentage of the variation of the dependent variable () can be explained by our model. The exact interpretation and derivation of the coefficient of determination can be found here.
The coefficient of determination shows how much of the variation of the dependent variable () can be explained by our model. Another way of interpreting the coefficient of determination , which will not be discussed in this post, is to look at it as the squared Pearson correlation coefficient between the observed values and the fitted values . Why this is the case exactly can be found in another post.
The following article tries to explain the Balance Statistic sometimes referred to as Saldo or Saldo Statistic. It is used as a quantification method for qualitative survey question. The benefit of applying the Balance Statistic arises when the survey is repeated over time as it tracks changes in respondents answers in a comprehensible way. The Balance Statistic is common in Business Tendency Surveys.
Stochastic Independence versus Stochastic Dependence
In order to fully understand the Bayesian rule it is important to be familiar with some concepts of standard probability theory. Assume we have two events, let’s call them A and B. The probability that event A occurs is P(A) and the probability that event B occurs is P(B). If event A and event B are independent from each other, the probability that both events are occurring at the same time, also known as the joint probability .

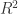 is to see it as the percentage of the variation of the dependent variable
is to see it as the percentage of the variation of the dependent variable 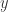 (
(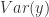 ) can be explained by our model. The exact interpretation and derivation of the coefficient of determination
) can be explained by our model. The exact interpretation and derivation of the coefficient of determination 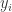 and the fitted values
and the fitted values 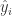 . Why this is the case exactly can be found in another
. Why this is the case exactly can be found in another 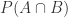 .
.