
In this post I am going to explain how to upgrade Debian 8 to Debian 9. You can enter the following eight steps in your terminal: Continue reading Upgrade Debian 8 to 9
Category Archives: Computing and Others
Linear Regression in STATA
In STATA one can estimate a linear regression using the command regress. In this post I will present how to use the STATA function regress to run OLS on the following model
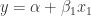
Cluster Robust Standard Errors in Stargazer
In a previous post, we discussed how to obtain clustered standard errors in R. While the previous post described how one can easily calculate cluster robust standard errors in R, this post shows how one can include cluster robust standard errors in stargazer and create nice tables including clustered standard errors.
Continue reading Cluster Robust Standard Errors in Stargazer
Robust Standard Errors in Stargazer
In a previous post, we discussed how to obtain robust standard errors in R. While the previous post described how one can easily calculate robust standard errors in R, this post shows how one can include robust standard errors in stargazer and create nice tables including robust standard errors.
Multiple Regression in Julia
Julia presents various ways to carry out multiple regressions. One easy way is to use the lm() function of the GLM package. In this post I will present how to use the lm() and run OLS on the following model

Linear Regression in Julia
Unfortunately, linreg() is deprecated and no longer exists in Julia v1.0. In case you are using Julia v1.0 or above, check out this post. In case you use a version of Julia that is older than 1.0, i.e 0.7, 0.6, etc., the following post will show you how to run a linear regression in Julia.
Julia presents various ways to carry out linear regressions. In this post I will present how to use the native function linreg() to run OLS on the following model
How to Read an Excel File dircetly form the Web in Julia Language?
In a former blog post (see here) I described how to read an Excel file into Julia. In this post I will focus on how to import an Excel file directly from the Web. This feature might be especially useful for recurring routines that rely on the most up-to-date data. Continue reading How to Read an Excel File dircetly form the Web in Julia Language?
Create Venn-Diagram in R
A Venn diagram (also sometimes also called primary diagram or set diagram) is a diagram that depicts all possible logical relations between a collection of sets. Certain subjects, such as omitted variable bias, can be best be explained by using a Venn diagram. This post shows how to construct a Venn diagram in R.
How to Read an Excel File in Julia Language? An example.
This article shortly describes how to read an Excel file into Julia. Generally, one can use different libraries to read Excel files, including XLSXReader , ExcelReaders or Taro. In this tutorial I will focus on Taro as it created the fewest problems and provides – at least in my eyes – an easy to understand syntax.
Continue reading How to Read an Excel File in Julia Language? An example.
Clustered Standard Errors in STATA
In STATA clustered standard errors are obtained by adding the option cluster(variable_name) to your regression, where variable_name specifies the variable that defines the group / cluster in your data. The summary output will return clustered standard errors. Here is the syntax:
regress x y, cluster(variable_name)
Below you will find a tutorial that demonstrates how to Continue reading Clustered Standard Errors in STATA
